What is edge AI deployment: a practical guide


Edge AI deployment is the process of running artificial intelligence inference models directly on local edge devices, enabling real-time decisions without cloud dependency. Gartner projects that by 2026, over 50% of new industrial IoT solutions will embed edge AI precisely because of this capability. The approach reduces bandwidth consumption by processing data locally and sending only insights upstream, not raw data. For tech professionals and business leaders, understanding what is edge AI deployment means understanding a fundamental shift in where intelligence lives inside an organisation’s infrastructure.
What is edge AI deployment and why does it matter?
Edge AI deployment moves AI inference from centralised cloud servers to the device where data originates. A factory camera running a defect detection model locally, a medical wearable classifying cardiac anomalies in real time, or a vehicle making split-second navigation decisions are all examples. Edge AI enables offline operation, reduced latency, privacy protection, and lower bandwidth costs compared to cloud AI processing.
One critical distinction separates edge AI from cloud AI: edge AI deployment is inference-only. Training large, compute-intensive models always happens in cloud environments. Edge devices only receive optimised, lightweight models. Attempting to run training workloads on edge hardware causes thermal failure and hardware damage. This is not a limitation to work around. It is the architecture’s defining boundary.
The business case is direct. Real-time decisions in autonomous navigation, predictive maintenance, and quality inspection cannot tolerate the round-trip latency of a cloud call. Training happens in the cloud, but edge deployment handles the mission-critical, low-latency applications that determine operational outcomes.
What are the common architectures for edge AI deployment?
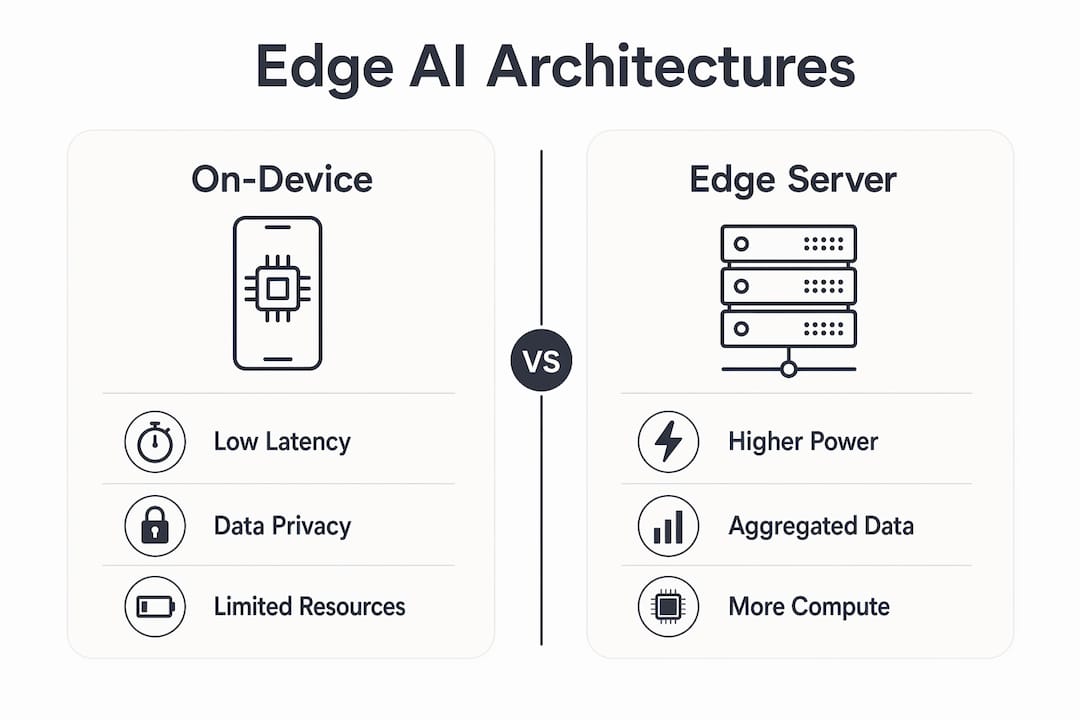
Common architectures include on-device AI, gateway edge, network edge, and hybrid edge-cloud. Each suits different combinations of latency requirement, privacy sensitivity, and available compute.
- On-device AI (pure edge): The model runs entirely on the endpoint device, such as a smartphone, industrial sensor, or camera. Latency is minimal and data never leaves the device. The trade-off is the tightest hardware constraint.
- Gateway edge: A local gateway aggregates data from multiple sensors and runs inference before forwarding results. This suits factory floors where individual sensors lack compute power but a local server can handle the model.
- Network edge (e.g. 5G towers): Inference runs at telecom infrastructure nodes. This suits connected vehicles and smart city applications where devices are mobile and the network itself provides compute proximity.
- Hybrid edge-cloud: Lightweight inference runs at the edge for time-sensitive decisions. Heavier analytics, model retraining, and audit logging happen in the cloud. Most enterprise deployments land here.
Choosing the right architecture depends on three variables: how much latency your application tolerates, how sensitive the data is, and what compute budget the device carries. A hybrid model suits most enterprise use cases because it balances real-time response with centralised governance.
Pro Tip: Map your latency requirements before selecting an architecture. If a decision must complete in under 50 milliseconds, pure edge or gateway edge is the only viable path. Hybrid models add network round-trip time for any cloud-bound step.
How does hardware and software alignment affect deployment success?
Hardware selection is the single decision that constrains every subsequent software choice. Typical edge devices carry 512MB, 8GB RAM with strict power and thermal limits. The processor type matters as much as the RAM figure. CPU-only devices handle simple classification tasks. GPU-equipped devices run convolutional neural networks. NPUs (neural processing units) and TPUs (tensor processing units) deliver the best performance per watt for dedicated inference workloads.
The software stack must align with the silicon from day one. Container orchestration tools such as K3s and MicroK8s are purpose-built for resource-constrained environments. They allow teams to deploy, update, and manage models across device fleets without the overhead of full Kubernetes. Choosing a container runtime that assumes abundant memory will cause failures on devices with 1GB RAM or less.
Key hardware and software alignment considerations:
- Processor type: Match the model’s compute graph to the available accelerator (CPU, GPU, NPU, or TPU).
- Memory budget: Quantised models (see the next section) must fit within the device’s available RAM with headroom for the operating system.
- Power envelope: Battery-powered devices require models optimised for low power draw, not just low latency.
- Orchestration tooling: K3s or MicroK8s for fleet management; avoid full Kubernetes on constrained hardware.
- Runtime compatibility: Frameworks such as TensorFlow Lite and ONNX Runtime are designed for edge inference. Full-size frameworks are not.
Deployment failures most commonly occur when teams select hardware after designing the software, or when they port a cloud-trained model to an edge device without checking memory and power budgets. The fix is simple: lock hardware specifications before writing a single line of deployment code.
Pro Tip: Build a hardware specification sheet before the software architecture review. Include RAM, processor type, thermal design power, and storage. Every software decision should reference this sheet.
What optimisation techniques are essential for edge AI models?
Model optimisation is not optional for edge AI deployment. Common failures occur because teams attempt to run unoptimised cloud models on constrained edge devices. The three primary techniques are quantisation, pruning, and compression.
Quantisation, pruning, and compression each reduce model size and power consumption while preserving as much accuracy as the hardware budget allows.
| Technique | What it does | Accuracy trade-off | Typical use case |
|---|---|---|---|
| Quantisation | Converts weights from FP32 to INT8, reducing model size by up to 4x | Minor accuracy loss, usually under 2% | General edge inference on NPU or CPU |
| Pruning | Removes redundant neural connections to reduce inference time | Moderate loss if aggressive; minimal if structured | Latency-critical applications |
| Knowledge distillation | Trains a smaller “student” model to mimic a larger “teacher” model | Depends on size gap | When a purpose-built small model is needed |
| Weight compression | Applies lossless or lossy compression to stored model weights | None to minor | Storage-constrained devices |
Quantisation from FP32 to INT8 is the most widely applied technique. It cuts model size by roughly 75% and reduces memory bandwidth requirements significantly. The accuracy loss is typically negligible for classification and detection tasks. Pruning removes connections that contribute little to the output. Structured pruning, which removes entire filters or layers, produces hardware-friendly speedups. Unstructured pruning produces smaller files but requires specialised hardware to realise the speed benefit.

The practical sequence is: quantise first, measure accuracy on a validation set, then apply pruning if further size reduction is needed. Compression applies at the storage layer and does not affect inference speed.
What are the operational challenges in managing edge AI deployments?
Managing a fleet of edge devices at scale is where most organisations underestimate the complexity. A pilot with five devices is straightforward. A fleet of 5,000 devices across remote sites is an operational discipline in its own right.
-
Pilot with a controlled subset. Start with pilot edge nodes to test model accuracy and system stability before scaling. Define pass/fail criteria for latency, accuracy, and uptime before the pilot begins.
-
Implement atomic OTA updates. Over-the-air updates must be atomic with rollback capability. An update that fails mid-write on a remote device in a warehouse or on a wind turbine cannot be recovered manually. Atomic updates either complete fully or revert to the previous state automatically.
-
Harden device security. Edge devices sit outside the data centre perimeter. Each device is a potential attack surface. Enforce signed firmware, encrypted model weights, and certificate-based authentication for all device-to-cloud communication.
-
Monitor model performance continuously. Accuracy degrades when real-world data drifts from the training distribution. Track inference confidence scores, prediction distributions, and hardware health metrics (temperature, memory usage, CPU load) from a central dashboard.
-
Plan for model refresh cycles. Edge AI models are not static. As operating conditions change, models need retraining in the cloud and redeployment to the fleet. Build this cycle into the operational calendar from the start.
Simulation-led testing combined with secure edge AI reduces downtime and accelerates decision-making. The biggest operational hurdle is managing the hardware, software, and security lifecycle at scale simultaneously. Organisations that treat this as a one-time deployment rather than an ongoing operational function consistently encounter fleet reliability problems within 12 months.
Key takeaways
Edge AI deployment succeeds when hardware selection, model optimisation, and lifecycle management are treated as a single integrated discipline rather than three separate workstreams.
| Point | Details |
|---|---|
| Inference only at the edge | Edge devices run optimised models; all training must happen in cloud environments. |
| Hardware drives every decision | Lock device specifications (RAM, processor type, power budget) before designing the software stack. |
| Optimise before you deploy | Quantisation and pruning are required steps, not optional improvements, for constrained devices. |
| OTA updates need rollback | Atomic over-the-air updates with automatic rollback prevent bricked devices in remote fleets. |
| Lifecycle management is ongoing | Model accuracy drifts over time; build refresh cycles and monitoring into operations from day one. |
Where most organisations get edge AI deployment wrong
Having built and operated AI agents across finance, legal, and GTM functions, I have watched organisations make the same mistake repeatedly: they treat edge AI deployment as a software project rather than a systems engineering discipline.
The hardware-software boundary is where most projects stall. Teams design elegant model architectures in cloud notebooks, then discover the target device has 1GB of RAM and no GPU. The retrofit is expensive and slow. The organisations that get this right start with a hardware specification review before the first model training run. That sequence feels counterintuitive to teams trained in cloud-first thinking, but it is the correct order.
The second pattern I see is underinvestment in lifecycle management for AI agents and edge models alike. Deployment is not the finish line. Model drift, security patches, and hardware failures are operational realities that require dedicated processes. Simulation-led testing before fleet rollout is one of the most underused practices I have encountered. It catches failure modes that only appear under real operating conditions, and it is far cheaper than a bricked fleet.
The emerging trend worth watching is specialised small language models running at the edge. As model compression techniques mature, the boundary between cloud-only LLM capability and edge-deployable intelligence is moving. Organisations that build their AI implementation strategy now with edge-aware architecture will have a structural advantage when that boundary shifts.
, Hayat
Meethayat’s AI Agent Operator service and edge AI strategy
Deploying AI at the edge requires the same operational rigour as deploying AI agents into finance or legal workflows. The model must fit the environment, the update cycle must be reliable, and the performance must be measurable.
Meethayat’s AI Agent Operator service supports enterprises in designing and operating AI deployments that match their infrastructure constraints and business objectives. Whether the challenge is selecting the right architecture, aligning hardware with model requirements, or building a lifecycle management process, the service brings three exits’ worth of operational discipline to the problem. For organisations weighing whether they need an operator or a consultant, the 2026 hire guide sets out the distinction clearly.
FAQ
What is edge AI deployment in simple terms?
Edge AI deployment is the process of running AI inference models on local devices rather than in the cloud. It enables real-time decisions without network dependency.
How does edge AI differ from cloud AI?
Cloud AI sends data to remote servers for processing. Edge AI processes data on the device itself, delivering lower latency, better privacy, and reduced bandwidth use.
What hardware is needed for edge AI deployment?
Edge devices typically carry 512MB, 8GB RAM with CPU, GPU, NPU, or TPU processors. Hardware selection must happen before software architecture is designed.
What is the biggest cause of edge AI deployment failure?
The most common cause is deploying unoptimised models that exceed the memory and power budgets of constrained edge devices. Quantisation and pruning resolve this before deployment.
Can edge AI devices train models locally?
No. Edge AI deployment is inference-only. Model training requires cloud-level compute. Attempting training on edge hardware causes thermal and hardware failure.