What is an AI pipeline? A guide for tech leaders


Most professionals working in AI-adjacent roles have encountered the term “AI pipeline” and assumed it refers to a data transport mechanism. That assumption is wrong, and it costs teams months of rework. An AI pipeline is not simply a data flow. It is an automated, end-to-end workflow managing every stage of the AI lifecycle, from raw data ingestion through to production monitoring and retraining. Understanding what an AI pipeline actually does, and how each stage connects, is the foundation for deploying AI that remains accurate, reliable, and governable at scale.
Table of Contents
- Key takeaways
- What is an AI pipeline and how does it work?
- AI pipelines vs traditional ETL: why the difference matters
- MLOps and CI/CD: the engineering backbone
- AI agent pipelines: chaining specialists for complex workflows
- My perspective on AI pipeline adoption
- Work with Meethayat on your AI pipeline
- FAQ
Key takeaways
| Point | Details |
|---|---|
| AI pipelines are full lifecycle systems | They manage data ingestion, training, deployment, and monitoring, not just data transport. |
| Quality gates prevent silent failures | Versioned artefacts at each stage catch data drift and model regressions before they reach production. |
| AI pipelines differ from ETL pipelines | AI pipelines require continuous ingestion and iterative retraining; traditional ETL is linear and batch-based. |
| MLOps treats pipelines as code | CI/CD integration enables repeatable, auditable deployments and automated retraining triggers. |
| Agent pipelines extend the model | Chaining specialised agents sequentially adds modularity and quality control to complex AI workflows. |
What is an AI pipeline and how does it work?
The most useful AI pipeline definition for practitioners is this: a structured, automated sequence of stages that takes raw data as input and produces a production-ready AI model as output, then continues to monitor and improve that model over time. Kestra describes it as the assembly line for AI, and the analogy holds because each station on that line produces a specific artefact that feeds the next.
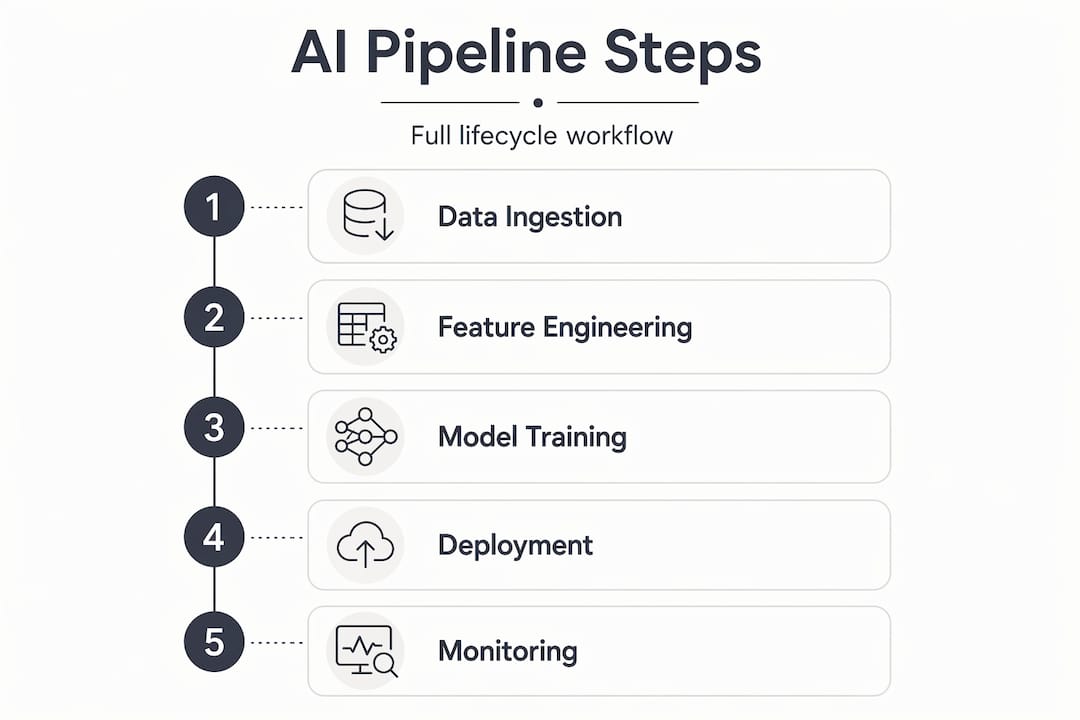
The AI development process follows five core stages, each with a defined output.
-
Data ingestion. The pipeline collects data from structured databases, APIs, streaming sources, and unstructured document stores. The output is a raw dataset. The quality of everything downstream depends on what enters here.
-
Data preparation and feature engineering. Raw data is cleaned, normalised, and transformed into features that a model can learn from. Domo identifies this as the stage that produces feature sets, the critical trust boundary between your data estate and your model training process.
-
Model training and validation. The pipeline trains candidate models against the feature set, evaluates them on held-out data, and selects the best performer based on defined metrics. Validation is not optional. Skipping it means deploying a model you have not measured.
-
Model deployment. Trained models are deployed as REST APIs for real-time inference, as batch jobs for scheduled scoring, or directly onto edge devices where latency or connectivity constraints apply. Each deployment pattern carries different monitoring requirements.
-
Monitoring and feedback loops. Production models degrade. Input distributions shift, user behaviour changes, and the world moves on. A functioning pipeline tracks model performance continuously and triggers retraining when drift crosses a threshold.
Pro Tip: Define your retraining trigger before you deploy. Teams that add monitoring retrospectively spend weeks reverse-engineering thresholds they should have agreed at design time.
The components of an AI pipeline are only as strong as the handoffs between them. Each stage must produce a versioned, documented artefact. Without that, diagnosing a production failure becomes guesswork.
AI pipelines vs traditional ETL: why the difference matters
Many organisations have mature ETL (extract, transform, load) pipelines and assume they can extend these to support AI workloads. The operational differences between the two are significant enough that this approach consistently fails.
| Dimension | Traditional ETL pipeline | AI pipeline |
|---|---|---|
| Data flow pattern | Batch, scheduled intervals | Continuous or near-real-time ingestion |
| Output | Populated data warehouse | Trained model artefacts and inference outputs |
| Iteration | Linear, run to completion | Iterative, with retraining loops |
| Artefact management | Table schemas and row counts | Datasets, feature sets, models, and metrics |
| Failure handling | Job retry or alert | Fallback inference, retraining trigger, drift alert |
dbt Labs makes the point directly: AI models require continuous or near-real-time data flow and automated retraining as new data arrives. A batch ETL job that runs at midnight does not satisfy that requirement for a model making real-time credit decisions or dynamic pricing calls.
The iterative nature of AI development also distinguishes the two. ETL pipelines are designed to run once, correctly. AI pipelines are designed to run repeatedly, improve with each cycle, and degrade gracefully when inputs fall outside expected parameters. Underestimating continuous ingestion needs is one of the most common and costly mistakes teams make when transitioning from BI-driven to AI-driven data architectures.

Pro Tip: If you are evaluating whether your existing data infrastructure can support an AI pipeline, ask one question: can it handle retraining triggers in response to live production signals? If not, you need a separate AI pipeline layer.
Artefact versioning is where many teams discover their ETL foundations are insufficient. Version control for table schemas is not the same as versioning the feature set a model was trained on. Failing to version dataset, feature, and model artefacts makes it genuinely difficult to diagnose data drift or unexpected model regressions in production.
MLOps and CI/CD: the engineering backbone
Understanding the AI pipeline stages is necessary but not sufficient. The question of how those stages run reliably in production brings you to MLOps, the discipline that applies software engineering rigour to machine learning workflows.
The central principle in modern MLOps is treating the entire pipeline as code. This means several things in practice:
- Version control for everything. Model training scripts, feature engineering logic, deployment configurations, and infrastructure definitions all live in source control alongside application code. This is not aspirational; it is the minimum bar for a pipeline you can debug.
- CI/CD automation. Databricks documents how production MLOps pipelines use automated testing and deployment of the AI development process as code, enabling repeatable releases and auditable change history.
- Environment parity. Development, staging, and production environments should run the same pipeline code with different data and configuration. Differences between environments are where silent failures originate.
- Automated retraining triggers. When monitoring detects drift or performance degradation, the CI/CD system kicks off retraining without requiring manual intervention. This closes the feedback loop that makes AI pipelines self-correcting rather than self-degrading.
Representing ML workflows as code enables systematic, predictable deployments and easier retraining through CI/CD integrations. For decision-makers, this translates directly: a well-engineered MLOps pipeline reduces the cost of deploying new model versions and makes it practical to iterate on model quality without a major engineering effort each time.
The agentic stack used by AI agent operators integrates naturally with these MLOps principles, extending pipeline governance into multi-agent orchestration layers.
AI agent pipelines: chaining specialists for complex workflows
The standard AI pipeline model assumes a single model at the inference stage. A growing pattern replaces that assumption with a chain of specialised agents, each handling one discrete task and passing its output to the next. This is the AI agent pipeline.
Ivern AI defines AI agent pipelines as sequences of specialised agents working in series, where each agent performs a specific stage such as research, drafting, review, or refinement, and hands off to the next. Consider a contract analysis workflow where one agent extracts clauses, a second classifies risk categories, a third cross-references precedent, and a fourth drafts a summary memo. No single model does all of this well. Specialised agents do.
The advantages over monolithic model pipelines are concrete:
- Quality control at each handoff. Each agent can be validated independently. A failure in clause extraction does not corrupt the risk classification; it triggers an error at a defined boundary.
- Modular replacement. When a better model for one task becomes available, you replace that agent without rebuilding the entire pipeline. This is operationally significant for teams working at scale.
- Parallelisation where logic permits. Agents with no dependency on each other’s outputs can run concurrently, reducing total latency for complex workflows.
- Auditability. Each agent produces a logged output. You can inspect what the research agent found, what the drafting agent produced, and where the review agent intervened. This matters enormously in regulated industries.
For enterprise teams building AI into legal, finance, or GTM workflows, the agent pipeline model offers a degree of governance and modularity that a single large language model call simply cannot match. Understanding how to hire an AI agent operator with genuine pipeline expertise is therefore a procurement decision, not just a technical one.
My perspective on AI pipeline adoption
In my experience working as an AI agent operator across finance, legal, and GTM contexts, the most common failure I see is not a technology problem. It is an architecture problem caused by building pipelines as a series of manual steps that someone has to remember to run.
I have seen teams spend six months training a model and then lose the ability to reproduce that model three months after deployment because no one versioned the training data or the feature logic. That is not a data science failure. It is a pipeline governance failure. Explicit quality gates and versioned artefact lineage are what separate pipelines that age well from ones that become technical debt within a year.
The second thing I would stress is monitoring. Most teams add it as an afterthought, if at all. Robust AI pipelines use run status tracking, provider awareness, persistent logging, and error classification to handle degraded states safely. In practice, this means your pipeline should know when it is producing unreliable outputs and should fail loudly rather than silently. A model that returns confident wrong answers is significantly more damaging than one that refuses to return an answer at all.
For tech leaders, my practical advice is to treat your AI pipeline as a product, not a project. It needs an owner, a roadmap, and a monitoring dashboard that someone reads every week. Organisations that get this right compound their AI investments. Those that do not spend most of their engineering capacity on remediation.
, Hayat
Work with Meethayat on your AI pipeline
Building and operating AI pipelines at enterprise scale requires more than tooling knowledge. It requires the judgement to design the right architecture for your specific workflow, governance requirements, and data constraints. Meethayat’s AI agent operator services are built specifically for organisations deploying AI into finance, legal, and GTM functions, where accuracy, auditability, and reliability are non-negotiable. From designing multi-agent pipeline architectures to integrating with your existing MLOps stack, Hayat Amin brings the operational depth of a three-times exited CFO and a practising AI agent operator. Organisations seeking enterprise-grade AI pipeline expertise are welcome to get in touch directly.
FAQ
What is an AI pipeline in simple terms?
An AI pipeline is an automated workflow that takes raw data, processes it, trains a model, deploys that model, and monitors its performance continuously. It replaces manual handoffs with repeatable, governed processes.
How does an AI pipeline differ from a data pipeline?
A data pipeline moves and transforms data; an AI pipeline also trains models, manages artefacts, handles deployment, and runs feedback loops for retraining. AI pipelines require continuous ingestion and iterative updates that traditional batch ETL pipelines are not designed to support.
What are the main components of an AI pipeline?
The five core components are data ingestion, data preparation and feature engineering, model training and validation, model deployment, and continuous monitoring with retraining triggers. Each produces a versioned artefact.
What is an AI agent pipeline?
An AI agent pipeline chains multiple specialised agents in sequence, where each agent handles one task and passes its output to the next. This approach improves quality, modularity, and auditability compared to single-model inference pipelines.
Why do AI pipelines need CI/CD integration?
CI/CD integration makes model deployments repeatable and auditable, automates retraining when performance degrades, and enables teams to release new model versions without manual intervention. Treating ML workflows as code is the foundational principle behind this approach.