What is a foundational AI model: the 2026 guide


A foundational AI model is defined as a large-scale AI system trained on broad, unlabeled data using self-supervision, then adapted to perform many different downstream tasks without being rebuilt from scratch. Stanford HAI coined this definition in August 2021, and it remains the standard reference point in 2026. Models like GPT-4o, Claude 3.5, and AlphaFold 3 are all foundational models. Each was trained once on vast, diverse data and then deployed across entirely different use cases. That single architectural decision, training for generality rather than specificity, is what separates foundational models from every AI paradigm that came before them.
What is a foundational AI model and how does it differ from traditional AI?
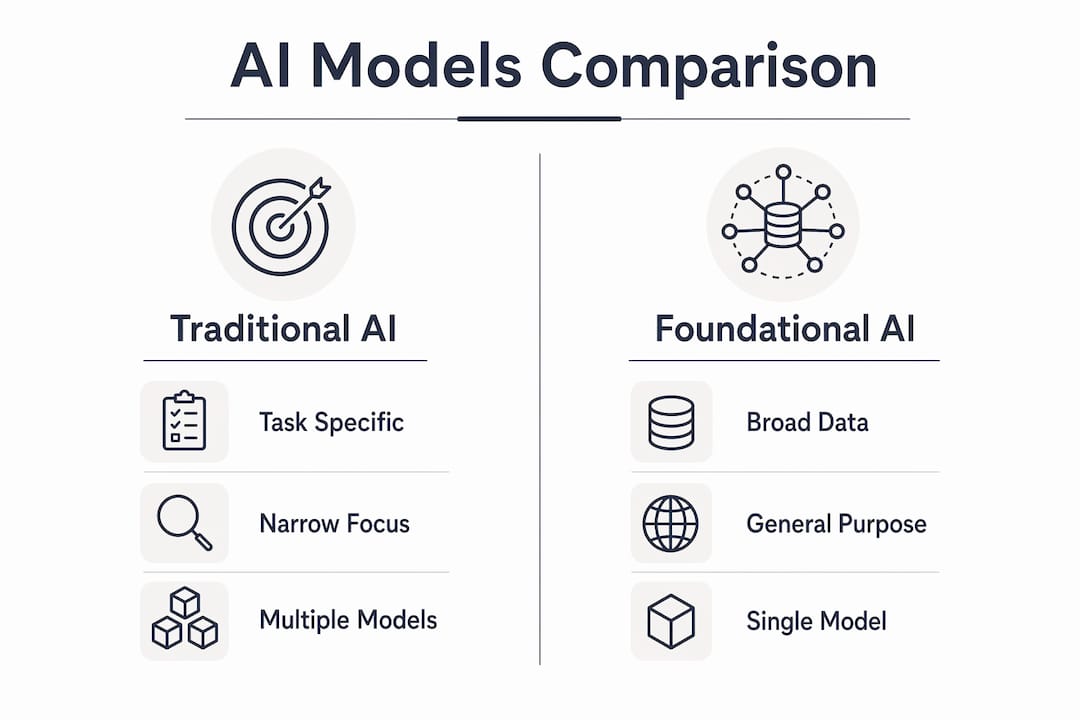
Traditional AI systems are built for one task. A fraud detection model detects fraud. A sentiment classifier classifies sentiment. Neither can do the other’s job without a complete rebuild. A foundational AI model breaks that constraint entirely.

Stanford’s 2021 definition describes foundational models as systems trained on unlabeled data at scale using self-supervision, producing a general-purpose substrate that can be adapted to many tasks. The word “foundation” is deliberate. These models serve as a base layer, not a finished product.
The three defining characteristics that separate foundational models from traditional AI are:
- Scale: Training datasets span billions to trillions of tokens drawn from text, images, code, audio, and scientific literature. No human labels the majority of this data.
- Generality: The same model can answer legal questions, summarise financial reports, generate code, and interpret medical scans. Task-specific AI cannot transfer across domains.
- Adaptability: Techniques including fine-tuning, prompt engineering, and in-context learning allow practitioners to specialise a foundational model for a specific domain without retraining it from the ground up.
This shift from task-specific to general-purpose AI is not incremental. It changes the entire economics of AI development.
Pro Tip: When evaluating whether a model qualifies as foundational, ask one question: was it trained once on broad data and then adapted, or was it built specifically for a single task? The answer determines its architectural category.
How have foundational models expanded beyond language?
The public narrative around foundational AI is dominated by large language models (LLMs) such as GPT-4o and Claude. That framing is too narrow. By 2026, foundational models cover vision, audio, robotics, and biology, and the trend is toward natively multimodal architectures that handle mixed inputs and outputs within a single model.
Consider the breadth of current examples:
| Domain | Model | Primary capability |
|---|---|---|
| Language | GPT-4o, Claude 3.5 | Text generation, reasoning, code |
| Vision | SAM (Segment Anything Model), CLIP | Image segmentation, visual understanding |
| Audio | Whisper | Speech recognition, transcription |
| Biology | AlphaFold 3 | Protein structure prediction |
| Robotics | HY-Embodied | Embodied intelligence, physical task execution |
Each of these models was trained on broad domain data and is adaptable to specific applications. AlphaFold 3, developed by Google DeepMind, is particularly instructive. It was not built to predict one protein. It was built to understand molecular structure at scale, and researchers now adapt it to drug discovery, materials science, and synthetic biology.
The move toward natively multimodal architectures is the most significant structural shift in this space. Earlier systems processed text or images separately. Models like GPT-4o accept text, images, and audio as a single input stream. That architectural change expands the definition of what a foundational model can do and compresses the number of specialised systems an organisation needs to maintain.
What are the practical benefits and challenges of adopting foundational models?
The commercial case for foundational models is grounded in efficiency. Foundation models reduce manual labelling needs and eliminate the requirement for bespoke AI programming across every new use case. That reduction in development overhead is the primary driver of enterprise adoption.
The healthcare sector provides the clearest quantitative evidence. A Stanford Medicine multi-centre study found that adapting an existing EHR foundation model required fewer than 1% of the data needed to train a locally built model, while achieving a 13% performance improvement in data-scarce settings. That result is not marginal. It means organisations operating in regulated, data-limited environments can deploy high-performing AI without the years of data collection that traditional approaches require.
The investment picture confirms the scale of industry commitment:
- Corporate AI investment reached $252.3 billion in 2024, the majority directed at foundational model development and deployment.
- Nearly 90% of notable AI models in 2024 originated from industry, not academia. That concentration reflects the compute requirements that only large organisations can currently fund.
- Training a frontier foundational model requires thousands of specialised GPUs running for months. The compute cost alone excludes most organisations from training their own models.
The challenges are real and should not be minimised. Compute costs remain prohibitive for independent developers. Training data volume requirements are enormous. And the concentration of foundational model development in a small number of large technology companies creates dependency risks for organisations that build on top of these systems.
Pro Tip: For most enterprises, the practical question is not whether to train a foundational model but which existing model to fine-tune and how to govern its outputs. That framing shifts the investment from compute to integration and oversight.
Foundation models vs LLMs, frontier models, and domain-specific architectures
These four terms are frequently conflated. They are not synonyms.
A large language model is a subset of foundational models. All LLMs are foundational models, but not all foundational models are LLMs. AlphaFold and Whisper are foundational models. Neither processes language as its primary modality.
A frontier model describes the current leading edge of capability within the foundational model category. The distinction between foundation models and frontier models is one of scope versus capability. Foundation model is the architectural category. Frontier model describes where the most advanced examples within that category currently sit. GPT-4o and Claude 3.5 Sonnet are both foundational models and frontier models. A fine-tuned legal document classifier built on top of GPT-4o is a foundational model derivative, not a frontier model.
Domain-specific foundational models occupy a third position. General foundation models built for scale contrast with vertical models that are smaller, cheaper, and superior in domain performance. A legal AI model trained primarily on case law, contracts, and regulatory filings will outperform GPT-4o on legal tasks while costing a fraction of the compute to run. The tradeoff is breadth. It cannot write marketing copy or interpret medical images.
The practical implication for technology professionals is this: model selection is a strategic decision, not a technical default. General foundational models offer breadth and rapid deployment. Domain-specific foundational models offer depth and cost efficiency. The right choice depends on the use case, the available data, and the organisation’s tolerance for vendor dependency.
What are the latest innovations shaping foundational AI in 2026?
The dominant trend in 2026 is a deliberate move away from the “bigger is better” doctrine that defined foundational model development from 2018 to 2023. Current industry trends focus on reasoning ability and efficiency over raw parameter count. OpenAI’s o-series models are the clearest public example of this shift. They are trained to reason through problems step by step rather than pattern-match at scale.
Three developments are reshaping the architecture of foundational models right now:
- Reasoning-focused training: Models are trained to allocate more computation to difficult problems rather than applying uniform processing to every query. This produces more reliable outputs on complex tasks without requiring larger models.
- Large-to-small on-policy distillation: Tencent’s HY-Embodied project demonstrated that high reasoning capabilities can be transferred from a 32-billion parameter model to a 2-billion parameter model without significant performance loss. That technique makes foundational model capabilities deployable on edge devices, which opens entirely new application categories in manufacturing, logistics, and consumer hardware.
- Embodied AI architectures: HY-Embodied’s Mixture of Transformers (MoT) architecture is designed for physical task execution, not just language or image processing. This represents the extension of foundational model principles into robotics and real-world interaction.
The combined effect of these trends is a broadening of who can deploy foundational AI. Distillation reduces compute requirements. Reasoning-focused training improves reliability. Multimodal and embodied architectures expand the range of tasks these systems can perform. The barriers to deployment are falling, even as the barriers to training remain high.
Pro Tip: Watch the distillation space closely. The ability to compress a 32B model into a 2B model without losing reasoning capability is what will make foundational AI accessible to organisations without hyperscale infrastructure.
Key takeaways
Foundational AI models are the defining architectural shift in modern AI: trained once on broad data, adapted to many tasks, and now expanding from language into vision, audio, biology, and robotics.
| Point | Details |
|---|---|
| Core definition | A foundational model is trained on broad, unlabeled data and adapted to many tasks without rebuilding. |
| Scale of investment | Corporate AI investment reached $252.3 billion in 2024, with 90% of notable models originating from industry. |
| Healthcare efficiency | Stanford research shows fewer than 1% of training data is needed when adapting an existing EHR foundation model. |
| Terminology precision | LLMs are a subset of foundational models; frontier models describe the current capability frontier within that category. |
| Emerging efficiency | Distillation techniques now compress 32B models to 2B without significant performance loss, enabling edge deployment. |
Why foundational models matter more than most organisations realise
Having spent time building and operating AI agents for enterprises, I find that most organisations are still thinking about foundational models as a technology question. They are not. They are a capital allocation question.
The concentration of foundational model development in a handful of companies, primarily in the United States, creates a structural dependency that most boards have not fully priced in. When you build your agentic stack on top of a single provider’s foundational model, you are not just making a technical choice. You are accepting a vendor relationship with significant switching costs and pricing power on the other side of the table.
The more interesting strategic question is not which foundational model to use today. It is how to architect your AI deployment so that the foundational model layer is interchangeable. The organisations getting this right are building abstraction layers between their business logic and the model provider. That approach costs more upfront and pays back substantially when model pricing shifts or a better option emerges.
The distillation trend is the most underappreciated development in this space. Smaller, capable models that run on your own infrastructure change the dependency calculus entirely. I expect the next two years to produce significant movement from hyperscale foundational models toward domain-specific, self-hosted alternatives for any organisation serious about data governance and cost control.
, Hayat
Deploy foundational AI models in your business with Meethayat
Meethayat’s AI agent operator services are built specifically for organisations that want to move from foundational model theory to working deployments. Hayat Amin designs and operates agentic stacks for finance, legal, and go-to-market functions, selecting the right foundational model layer for each use case and building the integration and governance architecture around it. If you are evaluating how foundational AI fits your operational model, the enterprise AI agent operator guide is the right starting point. This is not consulting. It is hands-on deployment by an operator who has built these systems in production environments.
FAQ
What is a foundational AI model in simple terms?
A foundational AI model is a large AI system trained on broad, diverse data that can be adapted to many different tasks. Examples include GPT-4o for language, AlphaFold for biology, and Whisper for audio.
How does a foundational model differ from a large language model?
All large language models are foundational models, but not all foundational models process language. AlphaFold and SAM are foundational models built for biology and vision respectively, with no primary language function.
What are the main examples of foundational AI models in 2026?
Notable examples span multiple domains: GPT-4o and Claude 3.5 for language, SAM and CLIP for vision, Whisper for audio, AlphaFold 3 for biology, and HY-Embodied for robotics.
Why do foundational models require so much investment to develop?
Training a foundational model requires thousands of GPUs running for months on datasets spanning billions of tokens. Corporate AI investment reached $252.3 billion in 2024, reflecting the compute and data costs involved.
Can smaller organisations use foundational AI models without training their own?
Yes. Most organisations access foundational models via APIs or fine-tune existing models on their own data. Distillation techniques now also enable deployment of compact, capable models on local infrastructure, reducing dependency on cloud providers.