The role of data in AI systems: a practitioner's guide


Most AI teams spend their time tuning model architectures, adjusting hyperparameters, and debating framework choices. Yet the role of data in AI systems is what actually determines whether a model succeeds or fails in production. The data-centric AI (DCAI) paradigm, which shifts focus from model iteration to systematic data quality management, is now reshaping how serious practitioners build and maintain AI. This guide covers what that shift means in practice: from data quality dimensions and governance requirements to semantic consistency, compliance under the EU AI Act, and continuous pipeline maintenance.
Table of Contents
- Key takeaways
- The data-centric AI paradigm
- Data quality dimensions and AI outcomes
- Data governance and semantic layers
- Building and maintaining data-centric pipelines
- My perspective on where this actually breaks down
- How Meethayat supports data-centric AI deployments
- FAQ
Key takeaways
| Point | Details |
|---|---|
| Data over model tuning | Iteratively refining data quality delivers more reliable performance gains than adjusting model architecture. |
| Five quality dimensions | Accuracy, completeness, consistency, timeliness, and representativeness are the pillars of training data that produces trustworthy outputs. |
| Governance is not optional | EU AI Act Article 10 mandates documented lineage, bias mitigation, and traceability for high-risk AI training datasets. |
| Semantics enable scale | A shared ontology or knowledge graph preserves business context across systems, preventing misalignment in AI decisions. |
| Continuous monitoring matters | Static validation at training time is insufficient; drift-aware monitoring is required throughout an AI system’s operational life. |
The data-centric AI paradigm
The term “data-centric AI” (DCAI) was popularised by Andrew Ng, but the underlying principle is straightforward: systematically engineer the data that feeds a model rather than treating data as fixed and iterating endlessly on the model itself. The DCAI lifecycle covers curation, enrichment, validation, and continuous monitoring, integrating techniques such as active learning and drift-aware quality controls.
This matters because the problems practitioners face in production rarely stem from the model. They stem from label noise, distribution shifts between training and inference data, and demographic biases baked into historical datasets. A well-specified transformer trained on inconsistent labels will underperform a simpler model trained on clean, representative data. That is the core argument for DCAI, and it is one the evidence consistently supports.
Common data issues that undermine AI performance include:
- Label noise: inconsistent or incorrect annotations that introduce systematic error into supervised learning
- Distribution shift: training data that does not reflect the statistical properties of live inference data
- Representation gaps: underrepresented subgroups that cause biased or unreliable outputs for specific populations
- Stale data: features or target variables that have drifted since data collection, making historical labels misleading
Focusing on these issues rather than model complexity leads to more robust outputs and simpler audit trails, both of which matter as regulatory scrutiny increases.
Pro Tip: Before tuning any model hyperparameters, run a data audit covering label consistency, class balance, and temporal coverage. In most cases, you will find more performance headroom in the data than in the model.
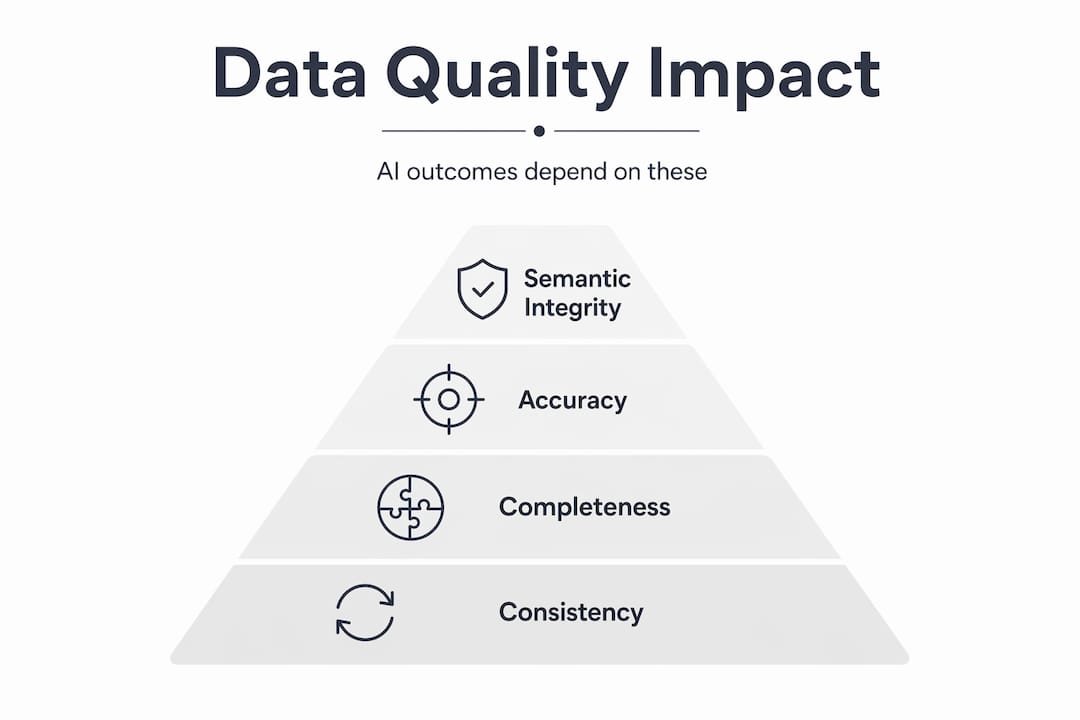
Data quality dimensions and AI outcomes
Poor data quality directly impacts AI model performance, producing biased or unreliable outputs. Studies indicate that 70 to 85% of AI failures are attributable to data issues rather than algorithmic limitations, with 96% of organisations reporting data quality problems during AI training. These are not edge cases. They are the default condition.
The five quality dimensions practitioners need to measure and manage are:
- Accuracy: Does each record correctly represent the real-world entity or event? In a credit scoring model, a single batch of mis-labelled defaults can corrupt a feature’s predictive signal entirely.
- Completeness: Are there systematic gaps? Missing values in clinical datasets, for instance, are rarely random. They often correlate with patient demographics, introducing bias that accuracy metrics alone will not surface.
- Consistency: Do records from different source systems agree? An inventory AI receiving contradictory stock counts from two warehouses will produce unreliable reorder recommendations regardless of its architecture.
- Timeliness: Is the data current enough for the prediction task? Fraud detection models trained on transaction patterns from eighteen months ago will miss emerging attack vectors entirely.
- Representativeness: Does the training set reflect the full distribution of cases the model will encounter in production? This is the dimension most commonly neglected in fast-moving projects.
The “garbage in, garbage out” principle is well understood in theory, but its AI-specific implications are more severe than in traditional analytics. A reporting query on bad data returns a wrong number. A model trained on bad data learns a wrong function and applies it at scale, potentially to millions of decisions before the problem surfaces.
Strategies for improving data quality include automated validation pipelines (schema checks, range assertions, cross-field consistency rules), targeted cleaning and deduplication, controlled data augmentation to address representation gaps, and synthetic data generation where real labelled examples are scarce. The last approach requires care: synthetic data that does not faithfully represent the generating distribution of real events can introduce its own biases.

Pro Tip: Treat data quality as a first-class engineering concern with defined SLAs. Set measurable thresholds for each quality dimension before training begins, and fail the pipeline automatically when those thresholds are breached.
Data governance and semantic layers
Governance in the context of AI means considerably more than maintaining a data catalogue. Effective governance covers the entire data transformation chain: lineage from source to feature store, policy enforcement on access and modification, traceability through preprocessing steps, and documented rationale for dataset design decisions.
The table below contrasts a traditional model-centric approach with a governance-first, data-centric approach across key operational dimensions.
| Dimension | Model-centric approach | Data-centric approach |
|---|---|---|
| Primary focus | Model architecture and hyperparameters | Data quality, lineage, and semantic consistency |
| Audit readiness | Limited; model versioning only | Full lineage from raw source to deployed feature |
| Bias mitigation | Post-hoc evaluation | Built into curation and validation pipelines |
| Regulatory posture | Reactive | Proactive; aligned with Article 10 requirements |
| Scalability | Constrained by data fragmentation | Enabled by federated, semantically aligned data fabric |
Article 10 of the EU AI Act places explicit obligations on providers of high-risk AI systems. It requires documented controls over training, validation, and test datasets, including design choices, collection methodologies, assumptions, bias examination procedures, and identification of gaps. Non-compliance is not a theoretical risk in 2026. It is an enforcement risk with material financial consequences.
Semantic consistency is the less-discussed half of this problem. AI model bottlenecks are frequently caused by data fragmentation and loss of semantic integrity rather than algorithmic gaps. When a “customer” in the CRM means something different from a “customer” in the billing system, any AI that joins those sources inherits that ambiguity. The model does not know; it learns whatever the conflicting signals encode.
A shared machine-readable ontology acts as a common language for scaling trustworthy AI across diverse organisational systems. Knowledge graphs take this further by encoding relationships between entities, allowing an AI to reason within business context rather than treating records as isolated rows. A strong data fabric with governance and semantic alignment creates a unified platform where AI systems can interpret business context effectively, making decisions that reflect organisational intent rather than statistical artefacts.
Building and maintaining data-centric pipelines
Translating DCAI principles into production requires treating data pipelines with the same engineering rigour applied to model training code. The following practices are foundational.
-
Continuous drift monitoring: Static dataset validation at training time is insufficient for deployed AI. Ongoing monitoring for feature drift, label drift, and prediction distribution shifts should be built into the operational pipeline from day one. When drift is detected, the response must be defined in advance: retrain, alert, or degrade gracefully.
-
Enrichment and annotation workflows: Data curation is not a one-time activity. Enrichment pipelines should continuously append new signals, correct historical errors identified during monitoring, and re-annotate samples where label quality is questioned. Active learning loops, where the model identifies its own uncertainty and routes those samples for human review, are particularly effective for annotation-scarce domains.
-
Synthetic data generation with validation gates: Synthetic data can close representation gaps, but only if it passes statistical equivalence tests against real distributions. Generating synthetic records without validation gates introduces a new class of data quality problem in place of the original one.
-
Lineage and reproducibility controls: Lineage coverage approaching 0.91 and reproducibility at 92% reduces investigation and audit preparation time by over 60%. Treating provenance as operational metadata rather than a compliance afterthought means that when an incident occurs, the root cause in the data pipeline can be identified in hours rather than weeks.
-
Iterative dataset versioning: Every change to a training dataset should be versioned and linked to the model run that consumed it. This is the data equivalent of git for model code, and it is equally non-negotiable for serious AI operations.
For practitioners working in financial services, where the impact of data on machine learning directly affects regulatory capital models and fraud systems, these controls are not merely best practice. They are the minimum viable standard.
My perspective on where this actually breaks down
I have worked with enough AI deployments, as both a CFO evaluating ROI and as an AI agent operator building production systems, to see the same failure pattern repeat itself. Teams invest months in model selection and almost nothing in data stewardship. They get a model into production, performance degrades within two quarters, and the diagnosis is invariably the same: the data drifted and nobody was watching.
The uncomfortable truth is that data governance is treated as an infrastructure concern rather than a product concern. Nobody owns it. The data team thinks the AI team should handle it; the AI team thinks the data team already did. The result is a governance vacuum where lineage goes undocumented, semantic mismatches accumulate, and compliance becomes a scramble when an audit arrives.
What I have found works is assigning explicit ownership of data quality SLAs at the same level of accountability as model performance metrics. When a data engineer is responsible for completeness scores the same way a product manager is responsible for user retention, the behaviour changes. The monitoring gets built. The pipelines get maintained.
I have also seen the semantic layer problem dismissed as an academic concern until an AI system trained on merged CRM and ERP data starts recommending credit terms to customers who have already churned. Ontologies are not theoretical niceties. They are the difference between an AI that reflects your business and one that reflects your data’s inconsistencies.
The practitioners who build durable AI systems invest early in data fabric architecture, governance policies with teeth, and continuous monitoring pipelines. Those who do not spend the second year of their AI programme undoing the first.
, Hayat
How Meethayat supports data-centric AI deployments
Building a production-grade AI system without a data governance foundation is a liability, not an asset. Meethayat, through Hayat Amin’s work as an AI agent operator, supports SMEs and larger organisations in designing and operating agentic stacks where data quality, lineage, and semantic consistency are built into the architecture from the start. Whether you need help structuring a data curation pipeline, mapping governance requirements under the EU AI Act, or deploying agents with drift-aware monitoring, the work starts from the data layer up. If you are deciding whether to hire an operator or a consultant for your next deployment, the 2026 hire guide at Meethayat covers exactly that decision.
FAQ
What is the role of data in AI systems?
Data is the primary determinant of AI system performance, reliability, and fairness. Studies show that 70 to 85% of AI failures trace back to data quality and governance deficits rather than model architecture limitations.
Why does data quality matter more than model choice?
A model trained on clean, representative, consistently labelled data will outperform a more complex model trained on poor data. The DCAI paradigm formalises this by prioritising curation, validation, and continuous monitoring over model iteration as the primary improvement lever.
What does Article 10 of the EU AI Act require?
Article 10 requires providers of high-risk AI systems to implement documented governance over training, validation, and test datasets, covering design choices, collection methods, bias examination, and traceability throughout the data lifecycle.
How does a data fabric improve AI outcomes?
A data fabric with semantic alignment enables AI systems to interpret data within business context, preventing fragmentation and semantic mismatches that cause AI decisions to misrepresent organisational intent.
How often should AI training data be reviewed?
Continuously. Static validation at training time does not address drift in deployed systems. Feature drift, label drift, and distribution shifts require ongoing monitoring pipelines that trigger defined responses when thresholds are breached.