Role of embeddings in AI: a technical guide for 2026


Embeddings are defined as learned numerical vector representations of data that preserve semantic relationships, mapping similar inputs close together in a continuous vector space. Text, images, audio, and graphs all compress into lower-dimensional vectors that models can compare, cluster, and retrieve. This is the foundational mechanism behind semantic search, retrieval-augmented generation (RAG), and multimodal AI. Without embeddings, large language models (LLMs) such as GPT-4 and Claude cannot reason about meaning. They can only process tokens. The role of embeddings in AI is therefore not peripheral. It is structural.
How do embeddings work and represent semantic relationships?
Embeddings are created during model training. A neural network learns to map inputs into a continuous vector space such that semantically similar items land near each other. The geometry of that space encodes meaning. “King” minus “man” plus “woman” produces a vector close to “queen.” That is not a coincidence. It is the model learning relational structure from data.
The mechanics of similarity comparison rely on distance metrics. Cosine similarity is the most widely used metric for ranking embeddings, measuring the angle between two vectors rather than their absolute distance. A cosine score of 1.0 means identical direction. A score near 0 means orthogonal, or unrelated. This metric works well for text because it is scale-invariant, meaning a long document and a short query can still match if they share directional meaning.
Embeddings are not limited to text. The same principle applies across modalities:
- Text embeddings capture word, sentence, or document meaning. Models like OpenAI’s
text-embedding-3-largeproduce 3,072-dimensional vectors. - Image embeddings encode visual features. Convolutional neural networks (CNNs) and vision transformers (ViTs) both produce these.
- Audio embeddings compress spectral and temporal features into vectors for speech recognition and music retrieval.
- Graph embeddings represent nodes and edges numerically, enabling link prediction and fraud detection.
Each modality uses the same underlying principle: proximity in vector space equals semantic similarity in the real world.
Pro Tip: When selecting an embedding model, test it on your specific domain data before committing. General-purpose models trained on web text often underperform on legal, medical, or financial corpora where vocabulary is specialised.

What are the main applications of embeddings in AI systems?
The importance of embeddings in AI extends well beyond text classification. They underpin a wide range of production AI patterns, particularly those involving unstructured data.
-
Retrieval-augmented generation (RAG). Embeddings convert document chunks and user queries into vectors, which are stored in vector databases such as Pinecone, Weaviate, or pgvector. At query time, the system retrieves the nearest vectors and passes that context to an LLM. This overcomes the context window limit without fine-tuning the model.
-
Semantic search. Traditional keyword search matches exact strings. Embedding-based search retrieves results based on meaning. A query for “cardiac arrest” returns documents about “heart attack” because both map to nearby vectors. Elasticsearch and OpenSearch both support vector search natively.
-
Recommendation systems. Platforms like Spotify and Netflix embed user behaviour and item features into shared spaces. Nearest-neighbour retrieval then surfaces items close to a user’s preference vector. This replaces brittle rule-based systems with geometry.
-
Clustering and anomaly detection. Embeddings allow unsupervised grouping of documents, transactions, or support tickets without predefined labels. Outlier vectors, those far from any cluster centroid, flag anomalies. This is particularly useful in fraud detection and log analysis.
-
Agentic semantic memory. Embedding-based semantic memory allows AI agents to recall relevant past interactions selectively. Vector databases store summaries of prior sessions. The agent retrieves only the memories most relevant to the current task, rather than loading an entire conversation history into the context window.
-
Cross-modal retrieval. Multimodal embeddings allow a text query to retrieve images, or an image to retrieve related audio. This is the mechanism behind tools like Google Lens and DALL-E’s conditioning pipeline.
The common thread across all six patterns is the same: embeddings reframe natural language and perception problems as geometrical nearest-vector searches. That reframing is what makes them general-purpose.
What are the technical considerations when working with embeddings?
Embedding infrastructure is not plug-and-play. The engineering decisions made at setup have long-term consequences that are expensive to reverse.
| Consideration | Impact | Recommendation |
|---|---|---|
| Embedding model choice | Determines maximum achievable recall | Benchmark on domain data before committing |
| Chunking strategy | Affects what context is captured per vector | Match chunk size to query granularity |
| Distance metric alignment | Mismatches disable vector indexes | Use the same metric for indexing and querying |
| Re-embedding cost | Full corpus re-embedding required on model change | Treat model selection as a long-term architectural decision |
| Dimensionality | Higher dimensions increase accuracy but raise storage and latency costs | Profile trade-offs at target query volume |
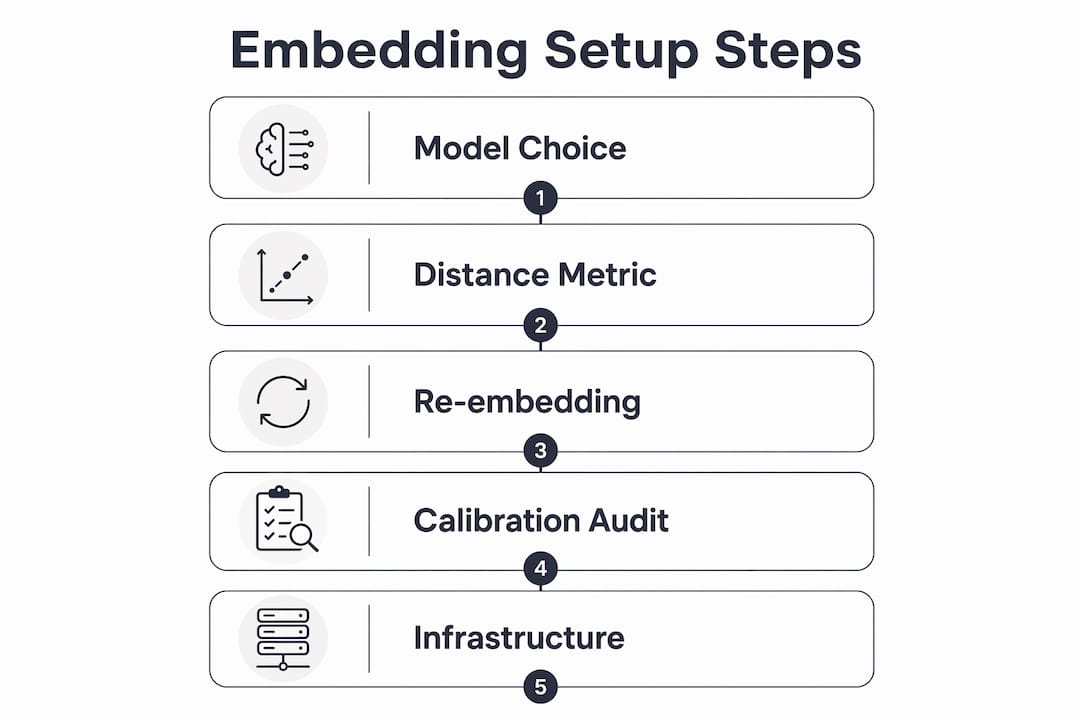
The most underestimated risk is model lock-in. Changing the embedding model requires re-embedding the entire corpus because stored vectors are model-specific. A corpus of ten million documents re-embedded at commercial API rates is not a trivial cost. Teams that treat embedding model selection as a modular decision often face significant regret when retrieval quality degrades and the only fix is a full rebuild.
Distance metric mismatches are a subtler failure mode. Vector search requires alignment between the metric used during index construction and the metric used at query time. A mismatch does not always produce an error. It silently changes search semantics, meaning your offline evaluation metrics no longer reflect production behaviour.
Retrieval quality is also capped by the embedding model itself. Reranking models such as Cohere Rerank or cross-encoders can improve the ordering of retrieved results, but they cannot recover chunks that the embedding model failed to retrieve in the first place. If a relevant document lands far from the query vector, no downstream component can surface it.
Pro Tip: Run an embedding calibration audit before deploying to production. Sample 200, 300 query-document pairs, compute cosine similarity scores, and inspect the distribution. If relevant pairs cluster below 0.7, your chunking strategy or model choice needs adjustment.
How are multimodal embeddings transforming AI?
Multimodal embedding models map different data types into a single shared vector space. Text, images, and audio align so that a sentence and a photograph depicting the same concept land near each other, even though they started as entirely different data formats.
The practical consequences of this are significant:
- Text-to-image retrieval becomes a nearest-neighbour search. A user types a description; the system returns the closest image vectors. Adobe Firefly and CLIP-based retrieval systems both operate on this principle.
- Image-to-text generation uses the image embedding as a conditioning signal for an LLM. The model generates a caption or answer grounded in the visual content.
- Cross-modal reasoning allows agents to process a PDF, an audio transcript, and a chart simultaneously, embedding each into the same space and reasoning across all three.
- Unified retrieval pipelines simplify architecture. Instead of maintaining separate indexes for text and images, a single vector database stores all modalities under one distance function.
The role of vector representations in AI is expanding precisely because multimodal alignment removes the artificial boundary between data types. Models like OpenAI’s CLIP and Google’s ImageBind demonstrate that a single embedding space can unify vision, language, and audio at scale. For AI researchers building production systems in 2026, multimodal embeddings are no longer experimental. They are a production-grade architectural choice.
Key takeaways
Embeddings are the foundational layer of modern AI systems, and the quality of your embedding infrastructure directly determines the ceiling of your model’s retrieval and reasoning performance.
| Point | Details |
|---|---|
| Embeddings encode semantic meaning | Similar inputs map to nearby vectors, enabling meaning-based comparison across text, images, and audio. |
| RAG depends on embedding quality | Retrieval recall is capped by the embedding model; reranking cannot recover what embeddings miss. |
| Model lock-in is a real cost | Changing embedding models requires full corpus re-embedding, making model selection a long-term architectural decision. |
| Metric alignment is non-negotiable | The distance metric used at index time must match the metric used at query time to avoid silent search failures. |
| Multimodal embeddings unify data types | Shared vector spaces allow text, images, and audio to be retrieved and reasoned about within a single pipeline. |
Embeddings in practice: what I have learnt building agentic systems
Most teams I encounter treat embedding selection as a configuration detail. It is not. It is the single most consequential architectural decision in any retrieval-based AI system, and it deserves the same scrutiny you would give a database schema.
The geometry problem is the part that surprises people. Embedding calibration is not about picking the highest-benchmark model. It is about ensuring that your specific query distribution and your specific document corpus produce a vector space where relevant pairs are genuinely close. I have seen systems where a top-ranked public model produced worse retrieval than a smaller, domain-fine-tuned alternative, purely because the domain vocabulary was out of distribution for the larger model.
Agentic workflows add another layer of complexity. When an agent needs semantic memory across hundreds of sessions, the chunking strategy for those memory summaries matters as much as the model itself. Chunk too coarsely and you retrieve irrelevant context. Chunk too finely and you lose the relational structure that makes a memory useful. The right answer is almost always domain-specific and requires empirical testing, not defaults.
My advice to researchers deploying embedding infrastructure: treat the first model choice as a long-term commitment, audit your similarity score distributions before going live, and build re-embedding costs into your operational budget from day one. The teams that do this avoid the most expensive mistakes in production RAG systems. For a broader view of how enterprise AI deployments handle embedding model selection at scale, the patterns are instructive.
, Hayat
Embedding-powered AI agents for your organisation
Meethayat builds and operates AI agents for SMEs that put embedding models to work in production, not in proof-of-concept notebooks.
The agents Meethayat deploys use embedding-based semantic memory and RAG pipelines to automate retrieval tasks across finance, legal, and GTM workflows. That means your agents recall relevant context from prior interactions, retrieve the right documents at query time, and reason across structured and unstructured data without manual intervention. If you are evaluating whether to hire an AI agent operator or an AI consultant for your embedding infrastructure, the distinction matters significantly for how your system gets built and maintained. Meethayat’s service page covers the full scope of what operator-led deployment looks like in practice.
FAQ
What are embeddings in AI?
Embeddings are numerical vector representations of data such as text, images, or audio that preserve semantic relationships. Inputs with similar meaning map to nearby positions in a continuous vector space.
How do embeddings work in retrieval-augmented generation?
In RAG, embeddings convert both document chunks and user queries into vectors stored in a vector database. At query time, the system retrieves the nearest vectors and passes that context to an LLM to generate a grounded response.
What is the biggest technical risk when using embeddings?
The primary risk is embedding model lock-in. Changing the model requires re-embedding the entire corpus, which carries significant operational cost and should be treated as a long-term architectural commitment from the outset.
What is a multimodal embedding model?
A multimodal embedding model maps different data types, such as text and images, into a single shared vector space. This enables cross-modal retrieval, where a text query returns the nearest image vectors using a consistent distance function.
Why does distance metric alignment matter in vector search?
Metric mismatches between index construction and query time silently alter search semantics and can disable vector indexes entirely, making offline evaluation metrics unreliable as a proxy for production performance.