AI agent data pipeline setup: 2026 SME guide


An AI agent data pipeline setup is the process of architecting automated workflows where AI agents manage data ingestion, transformation, quality checks, and orchestration to produce reliable, production-ready data flows. For data engineers at SMEs, the stakes are concrete: the Agentic Data Onboarding approach reduces pipeline development time from weeks to hours by coordinating approximately 15 AI sub-agents, generating pipelines in 10, 20 minutes. This guide covers the components, architecture patterns, step-by-step setup, and troubleshooting techniques you need to deploy confidently.
What components does an AI agent data pipeline require?
The foundation of any agentic pipeline is infrastructure that agents can read from, write to, and reason about. At minimum, you need object storage (AWS S3 buckets are the standard choice), encryption key management via AWS KMS, and an MCP server to handle agent-to-data-store communication. Without these three, agents have nowhere to securely ingest or stage data.
Orchestration sits above the infrastructure layer. Tools like Apache Airflow and Aqueduct handle DAG scheduling, dependency resolution, and retry logic. Airflow is the more mature choice for complex DAGs with many dependencies. Aqueduct is better suited to ML-centric workflows where pipeline stages map directly to model training or inference steps.

The Model Context Protocol (MCP) enables AI agents to query data stores dynamically, avoiding fragile point-to-point API integrations. MCP supports context stores including Redis and BigQuery, with read-only access as the default security posture. This matters because read-only access prevents agents from mutating source data during exploration or validation phases.
Sub-agents divide responsibility across the pipeline. A specification agent defines the schema and field semantics. A validation agent runs quality checks. An execution agent triggers the DAG run. An Agentcore gateway coordinates inter-agent communication and enforces guardrails. The table below summarises the core components.
| Component | Role | Example Tool |
|---|---|---|
| Object storage | Raw data ingestion and staging | AWS S3 |
| Orchestrator | DAG scheduling and dependency management | Apache Airflow, Aqueduct |
| Context protocol | Dynamic data store access for agents | MCP (Redis, BigQuery) |
| Sub-agents | Specification, validation, execution | AWS Agentic AI samples |
| Agentcore gateway | Inter-agent coordination and guardrails | AWS Agentcore |
Pro Tip: Configure your MCP server with read-only permissions by default. Grant write access only to the execution sub-agent, and only after the validation agent has confirmed data quality. This single guardrail prevents the most common class of agentic pipeline errors.
Which AI pipeline architecture pattern should you choose?
Seven production-grade patterns exist for AI agent pipelines, each with distinct latency, cost, and complexity trade-offs. Choosing the wrong pattern for your workload is the most expensive architectural mistake an SME data team can make.
Comparing the seven patterns
| Pattern | Agents | Latency | Parallelism | Best Use Case |
|---|---|---|---|---|
| Sequential | 2, 4 | High | None | Simple ETL, low data volume |
| Parallel | 4, 8 | Low | Full | Independent data source ingestion |
| Conditional | 3, 6 | Medium | Partial | Rule-based routing, compliance checks |
| Fan-out/Fan-in | 6, 12 | Low | Full | Multi-source aggregation |
| DAG | 5, 15 | Medium | Partial | Complex dependency chains |
| Iterative | 3, 6 | Variable | None | Self-correcting or retry-heavy workflows |
| Event-driven | 4, 20 | Very low | Full | Real-time data processing setup |
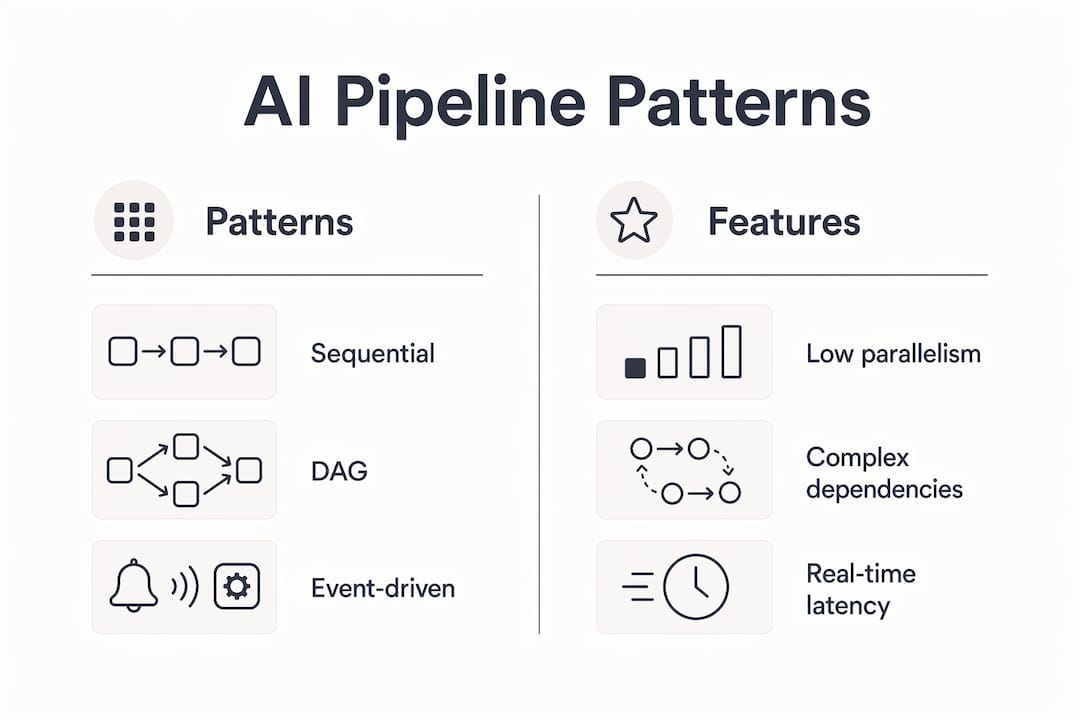
The Sequential pattern is the right starting point for SMEs with straightforward ETL requirements and limited agent budget. Each agent completes its task before the next begins. The trade-off is latency: a five-stage sequential pipeline is five times slower than a parallel equivalent.
The DAG pattern is the most common choice for production pipelines at SME scale. It handles complex dependency chains without requiring every stage to run in strict sequence. Airflow was built for DAG execution, which makes it the natural orchestrator when you select this pattern.
Event-driven pipelines suit real-time data processing where latency is the primary constraint. An event on a Kafka topic or an S3 PUT triggers an agent chain immediately. The cost is operational complexity: you need robust dead-letter queues and replay mechanisms before this pattern is production-safe.
Pro Tip: Start with a DAG pattern even if your initial workload looks sequential. DAGs give you the flexibility to add parallel branches later without redesigning the entire pipeline. Refactoring a sequential pipeline into a DAG mid-production is costly and disruptive.
How do you set up an AI agent data pipeline step by step?
A structured five-phase approach covers every production requirement from environment configuration through to live monitoring. Skipping any phase, particularly validation, is the primary cause of silent data quality failures in agentic systems.
Phase 1: environment setup
- Provision your S3 buckets (raw, staging, and curated zones) with separate KMS keys per zone.
- Deploy your MCP server and configure context store connections to Redis or BigQuery.
- Initialise your orchestrator. For Airflow, this means standing up the scheduler, webserver, and metadata database. For Aqueduct, install the server and configure your compute resource.
- Register your sub-agents with the Agentcore gateway and assign IAM roles with least-privilege permissions.
Phase 2: data onboarding and schema manifest definition
The Schema Manifest is a structured document that travels with each data record across the pipeline, describing field names, valid ranges, data types, and NULL semantics. Without it, downstream agents interpret fields differently, producing inconsistent outputs that are difficult to diagnose.
Your specification sub-agent generates the initial Schema Manifest by profiling the source data. You then review and annotate it manually before it enters the pipeline. This review step is non-negotiable: automated profiling misses business-specific NULL meanings (for example, a NULL in a revenue field may mean zero or may mean the record is incomplete).
Enrichment belongs at ingestion, not at query time. Attach human-readable labels to coded values during the ingestion stage so that records are self-contained when they reach downstream agents. This eliminates runtime lookup dependencies and the latency failures that accompany them.
Phase 3: multi-layer data quality gates
Three quality gate layers filter records before they reach agent consumption:
- Structural checks: field presence, data type conformance, and NULL constraints validated by Pydantic models.
- Semantic checks: value ranges, referential integrity, and business rule conformance (for example, a transaction date cannot precede the account creation date).
- Contextual checks: cross-record consistency, such as detecting duplicate transaction IDs or anomalous value distributions.
Most teams implement structural checks and stop there. Semantic and contextual checks catch the errors that structural validation misses, and those are precisely the errors that cause AI agents to produce confident but wrong outputs.
Phase 4: pipeline generation and deployment
With the Schema Manifest confirmed and quality gates passing, your execution sub-agent generates the DAG definition. In Airflow, this is a Python file defining tasks, dependencies, and retry logic. In Aqueduct, it is a pipeline object with typed inputs and outputs. The AWS Agentic AI samples framework achieves production readiness in 5, 10 minutes with 8 agents handling this generation phase. That speed is only achievable when the Schema Manifest and quality gates are already in place.
Phase 5: monitoring and observability
- Capture lineage metadata per OpenLineage specifications so every transformation is traceable.
- Set alerting thresholds on data volume, null rates, and processing latency at each stage.
- Log agent decisions, not just outcomes. Knowing that an agent chose to skip a record is as important as knowing the record was skipped.
Pro Tip: Treat your PipelineStage abstraction as a governance boundary, not just a code structure. Apply PII scrubbing and audit logging as declarative policies at the stage level so governance is consistent regardless of which agent runs the stage.
What are the most common AI agent pipeline failures?
Pipeline failures in agentic systems fall into four categories, and each requires a different diagnostic approach. Knowing the category before you start debugging saves hours.
Schema drift occurs when a source system changes a field name, type, or range without notice. The Schema Manifest becomes stale, and downstream agents begin misinterpreting records. The fix is automated schema comparison on every ingestion run, with a hard stop if the manifest diverges from the source profile.
Execution timeouts happen when an agent waits too long for a context store response or an external API. The diagnostic is straightforward: check MCP server logs for slow queries and review whether the context store is undersized for the data volume. Switching to a lower-tier model for non-critical sub-agents reduces compute time and often resolves timeout cascades.
Partial completions are the most dangerous failure mode. The pipeline appears to succeed but only processes a subset of records. Contextual quality gates catch this by monitoring record counts at each stage against expected volumes.
“Late enrichment is the single most repeated mistake in agentic pipeline design. Teams defer label attachment to query time, then discover at 2am that a lookup service is down and their entire agent chain is returning null outputs.” This is a pattern Meethayat observes consistently when auditing SME pipeline architectures.
Self-healing pipelines address recurring failures through structured PatchSpec objects. An agent identifies the failure, generates a patch specification describing the proposed code or configuration change, and submits it for multi-layer approval: compile checks, lineage verification, sandbox replay, and staged application. Agents never apply direct file or shell command mutations. This guardrail is what separates a self-healing pipeline from an autonomous system that corrupts its own codebase.
Key takeaways
A production-grade AI agent data pipeline requires a Schema Manifest, three-layer quality gates, and a DAG-based orchestration pattern to deliver consistent, auditable data flows at SME scale.
| Point | Details |
|---|---|
| Schema Manifest is non-negotiable | Every data record must carry field definitions, valid ranges, and NULL semantics across all pipeline stages. |
| Enrich at ingestion, not at query time | Attach labels and lookups during ingestion to eliminate runtime dependency failures. |
| Match architecture pattern to workload | Use DAG for complex dependencies, event-driven for real-time, and sequential only for simple ETL. |
| Three-layer quality gates catch silent errors | Structural checks alone miss semantic and contextual failures that cause agents to produce wrong outputs. |
| Self-healing requires structured patch approval | PatchSpec workflows with sandbox replay prevent agents from corrupting pipeline code during autonomous repairs. |
Why i build pipelines design-first, not code-first
Most SME teams I work with start by writing DAG code. They pick a tool, write a few tasks, and iterate from there. The pipeline works in development and breaks in production, usually within the first week of real data volume.
The reason is always the same: they skipped the Schema Manifest. Without a formal description of what the data means, not just what it looks like, agents at every stage make independent interpretations. Those interpretations diverge. By the time the divergence surfaces, it is embedded in three months of processed records.
My approach starts with governance as a cross-cutting concern, not an afterthought. Before a single line of DAG code is written, the Schema Manifest is reviewed, the quality gate policies are defined, and the PipelineStage abstraction is in place. This adds two to three days at the start of a project and saves two to three weeks of debugging later.
The other pattern I advocate for is continuous observability from day one. Teams treat monitoring as something they add after the pipeline is stable. Stability comes from monitoring, not the other way around. OpenLineage-compliant lineage capture and volume alerting should be live before the first production run.
For SMEs specifically, the cost and latency balance matters more than it does in enterprise settings. A fan-out/fan-in pattern with 12 agents is impressive on paper. If your data volume does not justify it, you are paying for parallelism you do not need. Start with a DAG pattern, measure your actual bottlenecks, and add agents where the data proves it is necessary. You can read more about choosing between operator and consultant support when deciding how to staff this work.
, Hayat
Need an AI agent operator to deploy your pipeline?
Building an agentic data pipeline is one thing. Running it reliably in production, with proper governance, observability, and self-healing capability, is a different discipline entirely.
Meethayat’s AI Agent Operator service covers the full deployment lifecycle: architecture design, Schema Manifest definition, quality gate configuration, orchestrator setup, and live monitoring. The service is built specifically for SMEs that need production-grade agentic infrastructure without the overhead of a large internal data engineering team. If you are at the stage of selecting tools or have an existing pipeline that is failing in production, get in touch to discuss a structured assessment and deployment plan.
FAQ
What is an AI agent data pipeline?
An AI agent data pipeline is an automated workflow where AI agents handle data ingestion, transformation, quality validation, and orchestration in place of manually coded scripts. The pipeline coordinates multiple sub-agents, each responsible for a specific stage, to produce reliable and auditable data flows.
How long does an AI agent pipeline setup take?
The Agentic Data Onboarding approach generates pipelines in 10, 20 minutes and achieves production readiness in 5, 10 minutes when using 8 coordinated sub-agents. Manual setup without agentic tooling typically takes days to weeks depending on complexity.
What is a schema manifest and why does it matter?
A Schema Manifest is a structured document that travels with each data record, describing field names, valid ranges, data types, and NULL meanings. Without it, agents at different pipeline stages interpret the same fields differently, producing inconsistent and unreliable outputs.
Which orchestration tool should i use: airflow or aqueduct?
Apache Airflow is the standard choice for complex DAG pipelines with many task dependencies and mature operational requirements. Aqueduct suits ML-centric workflows where pipeline stages map directly to model training or inference, and where the team prefers a Python-native interface over Airflow’s operator model.
How do self-healing pipelines work?
Self-healing pipelines use structured PatchSpec objects where an agent identifies a failure, generates a proposed fix, and submits it through compile checks, lineage verification, and sandbox replay before any change is applied. Agents never mutate files or execute shell commands directly, which prevents autonomous systems from corrupting their own pipeline code.