Agentic AI ops deployment guide for SMEs


IT operations in SMEs are drowning in noise. Alert volumes grow faster than teams can triage them, and traditional AIOps tools still require a human to interpret, decide, and act. This agentic AI ops deployment guide addresses that gap directly. Agentic AI operations move beyond passive monitoring into autonomous, policy-governed action: detecting anomalies, reasoning over context, and executing remediation without waiting for a ticket to be raised. With AI agent adoption rising to 54% of organisations in 2026, the window to deploy thoughtfully is now.
Table of Contents
- Key takeaways
- What agentic AI ops actually means
- Preparation: prerequisites and governance
- Step-by-step deployment guide
- Monitoring, auditing, and ongoing management
- Common challenges and how to avoid them
- My take on agentic AI ops
- Work with Hayat to deploy your agentic stack
- FAQ
Key takeaways
| Point | Details |
|---|---|
| Governance before automation | Establish RBAC, audit trails, and human-in-the-loop controls before any agent touches production. |
| Start with a bounded pilot | Choose one low-risk, high-value workflow to validate your AI deployment framework before scaling. |
| Treat agents as principals | Assign scoped identities and least-privilege access to every agent, exactly as you would a human operator. |
| Measure what matters | Track MTTR, false positive rates, and alert volume reduction from day one to prove operational value. |
| Scale iteratively | Add specialised agents only after the prior layer is stable, auditable, and producing consistent results. |
What agentic AI ops actually means
Traditional AIOps tools are, at their core, dashboards with smarter filters. They surface anomalies and correlate events, but a human still decides what to do next. Agentic AI operations change that contract entirely.
An agentic system perceives its environment through telemetry (logs, metrics, traces), reasons over that data using a language model or decision engine, selects an action from a defined policy space, and executes it autonomously. Agentic orchestration connects telemetry, reasoning, policy, and execution in a closed-loop system, which means the agent does not just detect a memory leak; it can restart the affected service, open an incident record, and notify the on-call engineer, all within seconds.
For SME IT teams, the practical benefits are significant:
- Reduced mean time to recovery (MTTR): Agents act on known remediation playbooks without waiting for human triage.
- Lower alert fatigue: Deduplication and correlation reduce the volume of noise reaching your engineers.
- Improved scalability: A three-person IT team can effectively supervise infrastructure that would previously require six.
- Consistent policy enforcement: Every action is governed by the same ruleset, removing ad-hoc decision variance.
- Auditability by design: Every agent action is logged against a defined policy, which matters enormously for compliance.
Common SME use cases include automated incident summarisation, log anomaly detection with self-healing scripts, certificate expiry management, and capacity scaling triggers. These are not exotic capabilities. They are operationally mature and deployable today with the right preparation.
Preparation: prerequisites and governance
The most common reason agentic AI deployments fail is not technical. It is organisational. Agentic AI forces organisations to redesign workflows and clarify roles for autonomous multi-step processes, often faster than governance structures can keep pace. Getting the groundwork right before you write a single line of agent configuration is non-negotiable.
Organisational readiness checklist:
- Define the specific use case the agent will own, with clear boundaries on what it can and cannot touch.
- Identify the human owner responsible for each agent’s behaviour and outcomes.
- Map existing ITSM, CMDB, and observability tooling to understand integration points.
- Confirm that logs, metrics, and traces are standardised and flowing into a unified observability platform.
Governance framework requirements:
- Role-based access control (RBAC) scoped to each agent’s function. Use role-separated identities with least privilege for every agent, and use proxy layers to enforce policies where APIs lack granularity.
- Human-in-the-loop checkpoints for any action that modifies production infrastructure.
- Policy-as-code definitions that are version-controlled and testable before deployment.
- Tamper-evident audit logs capturing requestor and agent identities, policies applied, approvals granted, and actions taken.
Security considerations:
Credential rotation and short-lived tokens reduce agentic AI compromise risk and prevent shadow IT from forming around your agent stack. Treat every agent as a service account with a defined identity lifecycle, not as a generic automation script.
Pro Tip: Before selecting a platform, map your existing observability gaps. An agent operating on incomplete or inconsistent telemetry will make confident decisions based on bad data. Fix the data first.
Governance per the NIST AI Risk Management Framework is not a one-time exercise. Effective governance is continuous and embedded throughout the AI lifecycle, requiring clear accountability structures and a genuine risk culture at the leadership level.
Step-by-step deployment guide
This is where most guides become vague. The steps below are sequenced for SME environments where you cannot afford a failed production rollout.
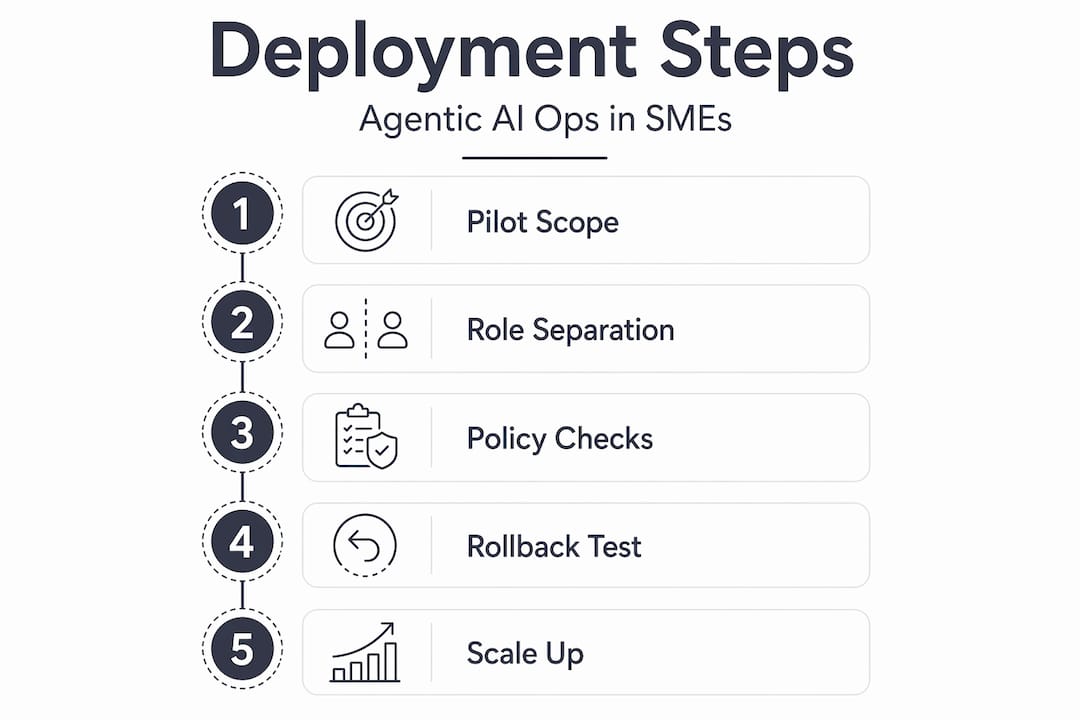
Step 1: Define the pilot scope
Start with low-risk, high-value use cases such as alert deduplication or incident summarisation. Choose a single workflow. Define success metrics before you begin: target MTTR reduction, alert volume change, and false positive rate. Set a pilot duration of four to six weeks.
Step 2: Design agent orchestration with role separation
Layer your agent roles deliberately. A well-structured agentic stack separates retrieval agents (pulling telemetry), reasoning agents (evaluating context against policy), approval agents (collecting human sign-off where required), and execution agents (taking the defined action). Layered roles mediated by scoped identities maintain auditability and prevent any single agent from having excessive authority.

Step 3: Implement policy checkpoints and risk-aware branching
Not every action should proceed automatically. Define risk tiers. Low-risk actions (restarting a non-critical service) can be fully autonomous. Medium-risk actions (modifying firewall rules) require a logged approval. High-risk actions (database schema changes) require synchronous human sign-off. This branching logic should be externalised as policy-as-code, not hardcoded into the agent.
Step 4: Build and test rollback mechanisms
Robust rollback patterns require splitting workflows into planning, validation, and execution phases, with checkpoints before any change is committed. Test your rollback procedures in a staging environment before the pilot goes live. A kill switch that halts all agent actions within 30 seconds is not optional; it is a deployment prerequisite.
Step 5: Scale beyond the pilot
Once the pilot meets its success metrics, you can add specialised agents for adjacent workflows. The table below compares pilot-stage and production-stage deployment characteristics.
| Dimension | Pilot stage | Production stage |
|---|---|---|
| Scope | Single workflow, non-critical | Multiple workflows, mixed criticality |
| Human oversight | High, frequent review | Selective, exception-based |
| Agent count | One to two agents | Five or more, orchestrated |
| Governance maturity | Draft policies, manual audit | Policy-as-code, automated audit |
| Rollback testing | Manual, staged | Automated, scheduled |
Pro Tip: Do not expand to a second workflow until your audit logs from the first are clean and your rollback has been tested successfully at least twice. Governance debt compounds quickly in agentic systems.
Monitoring, auditing, and ongoing management
Deploying the agent is not the finish line. Ongoing management is where the operational value either compounds or erodes.
Key performance indicators to track from day one:
- MTTR: Measure the change in mean time to recovery for incidents within the agent’s scope.
- Alert volume: Track week-on-week reduction in alerts reaching human engineers.
- False positive rate: Monitor how often the agent acts on a non-issue, which indicates telemetry quality problems.
- Policy compliance rate: Percentage of agent actions that followed the defined policy without exception.
- Audit trail completeness: Percentage of actions with a full, tamper-evident log entry.
Incident response protocols:
When an agent behaves unexpectedly, your response must be faster than a human-initiated incident. Activate the kill switch, preserve the audit log state, and initiate a post-incident review within 24 hours. Containment before investigation, always.
Periodic access review:
Every 30 days, review agent identities, credential expiry, and permission scopes. Remove any access that is no longer required for the current workflow. This is the agentic equivalent of a quarterly access review for human staff, and it carries the same compliance weight.
Continuous improvement:
Incorporate engineer feedback into agent training loops. When an agent makes a suboptimal decision, that event should feed back into policy refinement, not be dismissed as a one-off. This is how your agentic stack matures from reactive to genuinely proactive over time.
Common challenges and how to avoid them
Even well-prepared teams encounter predictable obstacles. Knowing them in advance reduces their cost.
- Insufficient governance at launch: Teams rush to automate and skip policy definition. The result is agents taking actions nobody explicitly authorised, which creates compliance exposure and erodes trust in the system.
- Role confusion: When it is unclear who owns an agent’s behaviour, nobody reviews its logs and nobody catches drift. Assign a named human owner to every agent before it goes live.
- Agent sprawl: Adding agents faster than governance can track them creates shadow automation. Maintain a registry of every agent, its scope, its owner, and its last audit date.
- Over-automation: Removing human oversight from too many workflows too quickly. The right balance is not maximum automation; it is maximum safe automation given your current governance maturity.
- Data quality issues: An agent operating on stale or inconsistent telemetry will produce confident but wrong decisions. Telemetry standardisation is a prerequisite, not a nice-to-have.
- Integration complexity: ITSM and CMDB integrations are rarely clean. Budget time for data mapping and API testing before the pilot begins.
Pro Tip: Run a tabletop exercise before your pilot goes live. Simulate an agent taking an incorrect action and walk your team through the kill switch, containment, and rollback procedure. Teams that have rehearsed this respond in minutes. Teams that have not respond in hours.
For additional context on how to structure roles and responsibilities around your agentic stack, the operator versus consultant distinction is worth understanding before you make any staffing decisions.
My take on agentic AI ops
I have built and operated agentic stacks for SMEs across finance, legal, and GTM functions. The pattern I see most often is this: organisations underinvest in governance because they are excited about automation, and then they lose trust in the system the first time an agent does something unexpected.
The uncomfortable truth is that governance is not a constraint on agentic AI. It is what makes agentic AI safe enough to actually use. Every pilot I have seen fail did so because human oversight was treated as a temporary inconvenience rather than a permanent design requirement.
My recommended approach is straightforward. Start with one workflow. Embed auditability from the first commit. Test your rollback before you need it. Scale only when the prior layer is stable and producing clean audit logs. The teams that follow this sequence end up with agentic stacks that compound in value over time. The teams that skip steps end up rebuilding from scratch after an incident.
Over the next five years, agentic AI ops will reshape SME IT operations more than cloud migration did. But the organisations that benefit most will not be the ones who moved fastest. They will be the ones who moved carefully, with governance embedded at every layer.
, Hayat
Work with Hayat to deploy your agentic stack
Hayat Amin has built and operated AI agent systems for SMEs across finance, legal, and GTM functions, bringing a CFO’s discipline to deployment decisions that most operators treat as purely technical. If you are planning your first agentic AI deployment or scaling beyond a pilot that has stalled, Hayat’s AI agent operator services cover the full stack: governance design, agent orchestration, integration with your existing ITSM and observability tooling, and ongoing management. For SMEs weighing whether to hire internally or engage an operator, the 2026 hire guide covers exactly that decision. Get in touch through meethayat.com to discuss your deployment context.
FAQ
What is agentic AI ops?
Agentic AI ops refers to IT operations where AI agents autonomously detect, reason over, and remediate infrastructure issues under defined policies, without requiring human intervention for every action.
How do I start deploying agentic AI operations in an SME?
Begin with a single low-risk workflow such as alert deduplication, define success metrics, establish governance and rollback mechanisms, and run a four-to-six-week pilot before expanding.
What governance controls are required for agentic AI deployment?
At minimum, you need RBAC with scoped agent identities, human-in-the-loop checkpoints for medium and high-risk actions, policy-as-code definitions, and tamper-evident audit logs for every agent action.
How do I measure success in an agentic AI ops deployment?
Track MTTR reduction, alert volume change, false positive rate, policy compliance rate, and audit trail completeness from the start of your pilot through to production.
What is the biggest risk in agentic AI ops deployment?
Insufficient governance is the most common failure point. Agents operating without clear policy boundaries, named owners, and tested rollback mechanisms create compliance exposure and erode organisational trust in the system.